Phân tích dữ liệu lớn với Apache Pig trên AWS Elastic MapReduce
Chia sẻ bài viết
Mục lục
Bạn gặp khó khăn khi cấu hình Hadoop Cluster dưới on-premise để xử lý dữ liệu lớn?
Hãy đọc bài viết này để tìm hiểu cách có thể giúp bạn tối ưu hóa gấp 10x thời gian đó.
1. Giới thiệu về Apache Pig:
Pig là một dự án nghiên cứu được bắt đầu bởi Yahoo và năm 2006. Hai năm sau, vào năm 2008 Apache Pig được phát hành phiên bản đầu tiên.
Apache Pig là một nền tảng ngôn ngữ cấp cao. Để phân tích và truy vấn dữ liệu lớn được lưu trữ trong HDFS của một Hadoop Cluster.
Ngoài ra, Pig còn cung cấp một ngôn ngữ cấp cao để viết các chương trình phân tích dữ liệu gọi là Pig Latin, khá giống với SQL. Pig latin cho phép Data Analyst viết các câu truy vấn và phân tích. Thậm chí có thể sử dụng Pig latin để tạo ra ETL pipeline.
Trong bài viết này, tôi sẽ tập trung vào việc xây dựng hệ thống Hadoop Cluster cài đặt Pig. Và sử dụng vài task Pig latin căn bản nhằm cung cấp một cái nhìn tổng quan về việc phân tích dữ liệu với Pig.
2. Giới thiệu AWS Elastic Mapreduce:
Việc ứng dụng Hadoop Cluster bên dưới on – premises có nhiều hạn chế, nên tôi đã triển khai phương án trên điện toán đám mây. Để bổ sung những khuyết điểm của Hadoop Cluster bên dưới on – premises. Việc triển khai Hadoop Cluster để sử dụng phân tích bằng Pig trên AWS hỗ trợ doanh nghiệp dễ dàng mở rộng, chịu lỗi cao và đáp ứng tính sẵn sàng.
AWS Elastic MapReduce là nền tảng dữ liệu lớn trên nền tảng đám mây hàng đầu. Để xử lý lượng lớn dữ liệu bằng các công cụ nguồn mở như Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi và Presto. Amazon EMR giúp chúng ta dễ dàng thiết lập, vận hành và mở rộng môi trường dữ liệu lớn bằng cách tự động hóa các tác vụ tốn thời gian như cung cấp dung lượng và tinh chỉnh các cluster. Với EMR, bạn có thể chạy phân tích ở cấp độ petabyte với chi phí ít hơn một nửa so với các giải pháp tại chỗ truyền thống và nhanh hơn gấp 3 lần so với Apache Spark tiêu chuẩn. Chúng ta có thể chạy khối lượng công việc trên các phiên bản Amazon EC2, trên các cụm Amazon Elastic Kubernetes Service (EKS) hoặc tại chỗ bằng cách sử dụng EMR trên AWS Outpost
3. Xây dựng hệ thống Hadoop Cluster
Chuẩn bị dữ liệu:
Dữ liệu về các loại bia được lấy từ nguồn Kaggle: https://www.kaggle.com/gauravharamkar/beer-data-analytics và upload lên AWS S3 Bucket. Việc sử dụng phân tích bia đang nổi lên và đương nhiên, các nhà sản xuất bia có lượng dữ liệu lớn nhất sẽ có lợi thế hơn. Các nhà máy bia đã và đang sử dụng dữ liệu để thúc đẩy các chiến lược tiếp thị của họ. Sử dụng các khía cạnh khác doanh số bán.
Bộ dữ liệu này chứa thông tin về các loại bia khác nhau và các khía cạnh khác nhau của nó. Như phong cách bia, khối lượng bia tuyệt đối, tên bia, tên nhà sản xuất bia. Dữ liệu bia giúp các nhà máy bia hiểu được hành vi của người tiêu dùng và có thể cải thiện do hình thức bia, hương vị bia, mùi thơm của nó, xếp hạng tổng thể, đánh giá, vv.
Kiến trúc hệ thống
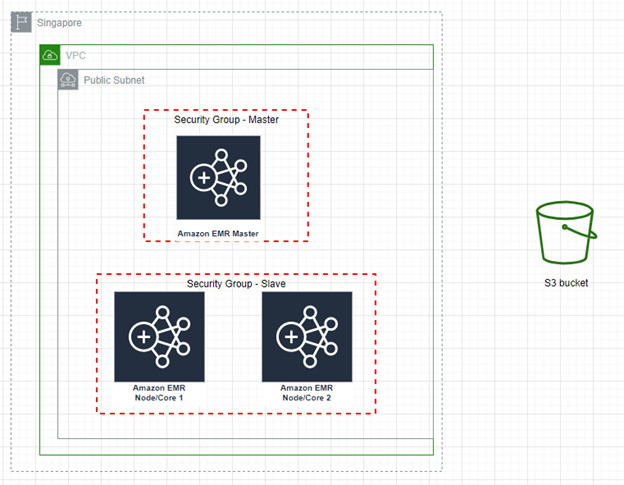
Hệ thống Hadoop Cluster được tạo ra bằng AWS Elastic MapReduce tự động tạo ra các instances AWS EC2. Phân quyền tự động cho các EC2 thành Master node và Slave nodes. Hadoop Cluster sẽ được cấu hình tự động Pig 0.17.0 và Hadoop 2.10.1.
Hadoop Cluster này sẽ được bảo vệ bằng cách đặt trong lớp Public Subnet. (Cách đặt tên ngụ ý cho phép dữ liệu được phép ra vào lớp mạng ảo) nằm trong lớp mạng ảo VPC. Và việc tạo lớp mạng ảo VPC nhằm mục đích tách biệt các Hadoop Cluster khác nhau (trong trường hợp có nhiều Hadoop Cluster).
Hadoop Cluster này sẽ được đặt tách ra từng Security Group riêng biệt cho Master và Slave. Nhằm mục đích giới hạn các Port và IPs được đi vào hệ thống trong Public Subnet.
Các dữ liệu lưu trữ của Hadoop Cluster, cụ thể là các file log, dữ liệu sử dụng và kết quả sẽ được lưu trữ tại S3 Bucket, là một features của dịch vụ lưu trữ dữ liệu dạng object, Simple Storage Service – AWS S3.
Phân vùng của máy chủ đang lưu trữ Hadoop Cluster là Asia Pacific (Singapore)ap-southeast-1.
Cài đặt Hadoop Cluster
1 Thiết lập VPC
Tiến hành thiết lập VPC trong AWS VPC
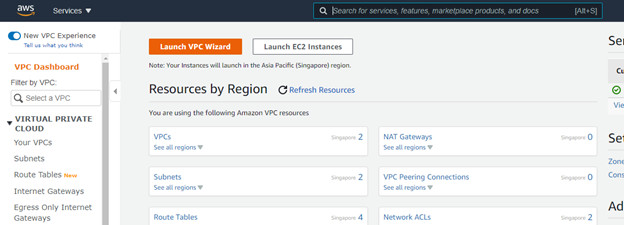
Bước 1 Thiết lập chọn Launch VPC Wizard
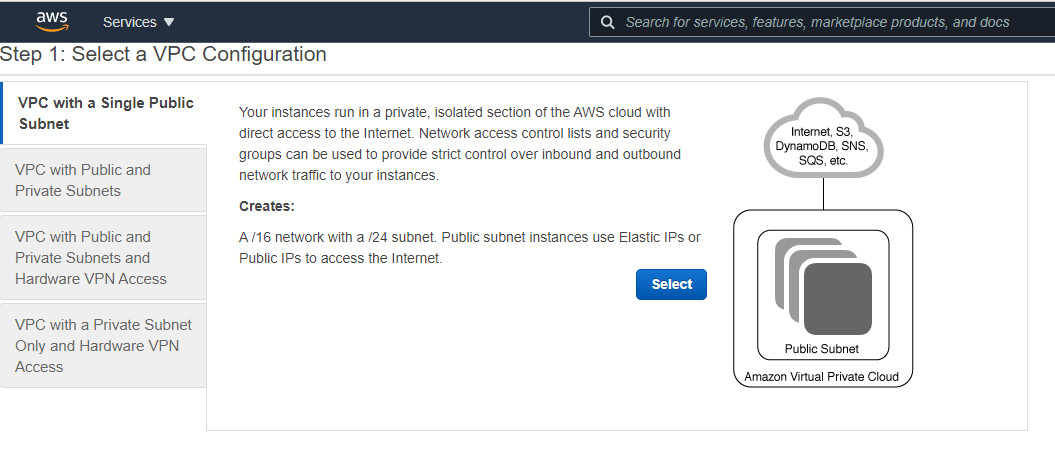
Bước 2. Chọn chủ đề có sẵn của VPC. VPC với 1 Public Subnet, bấm chọn Select
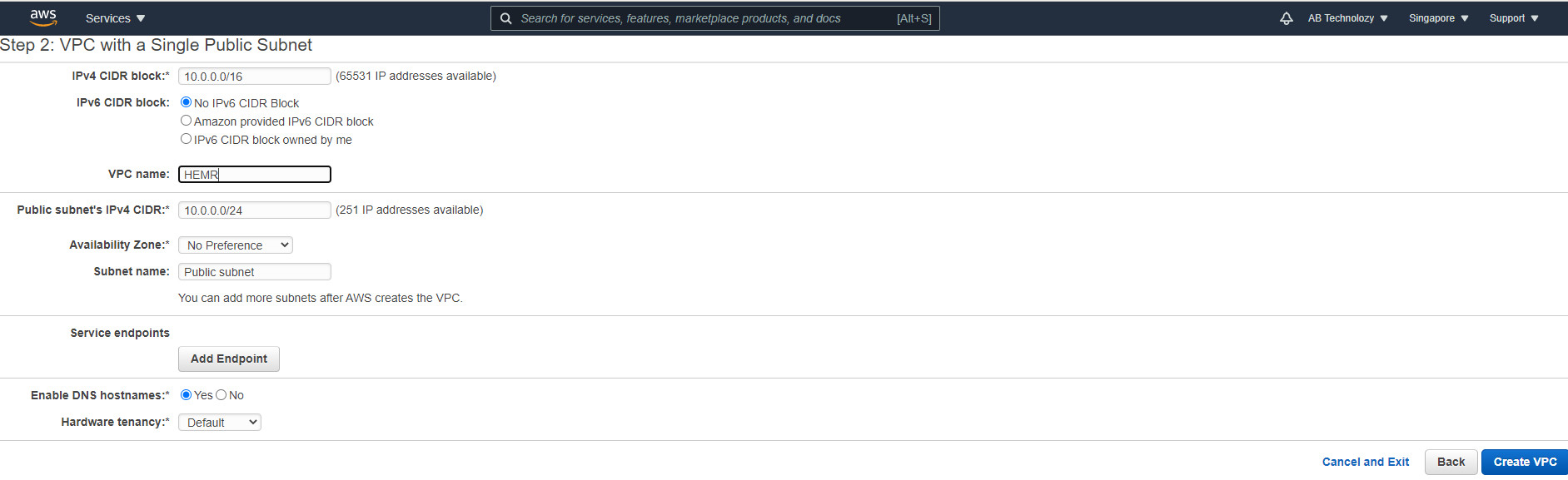
Bước 3 Đặt tên VPC và cấu hình các địa chỉ IPs (nếu cần). Chọn Create VPC để tạo
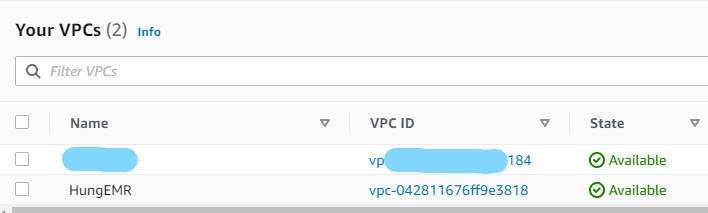
Bước 4 Đã tạo thành công VPC.
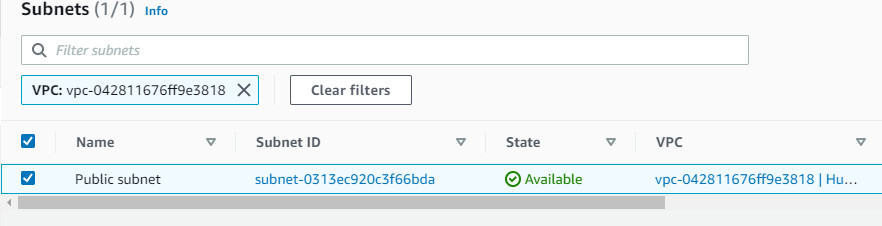
Bước 5 Xác nhận lại Public Subnet đã được tạo.
2 Thiết lập Key Pair cho Instance EC2 – Master.

Bước 6 Tạo Key Pair trong AWS EC2.
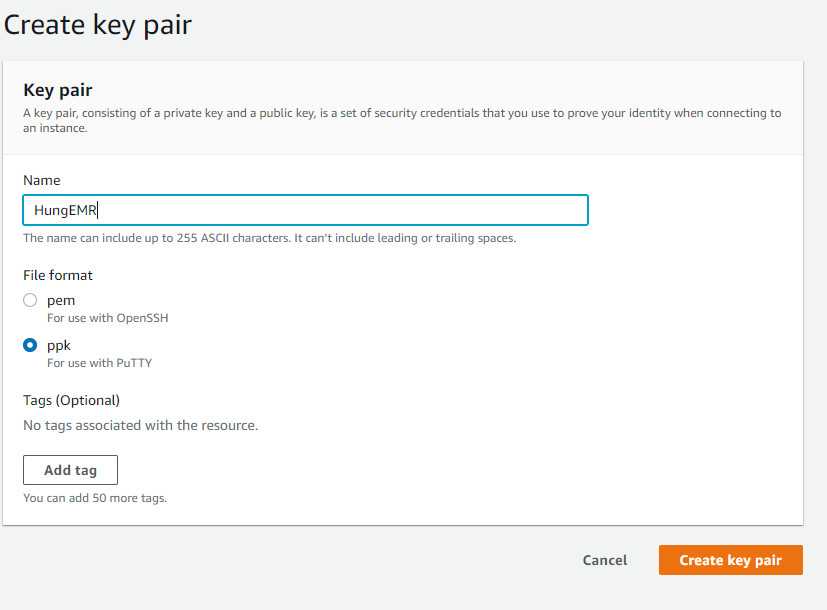
Bước 7 Đặt tên, chọn định dạng file ppk để có dễ dàng SSH vào EC2 Master. Chọn tạo Key Pair
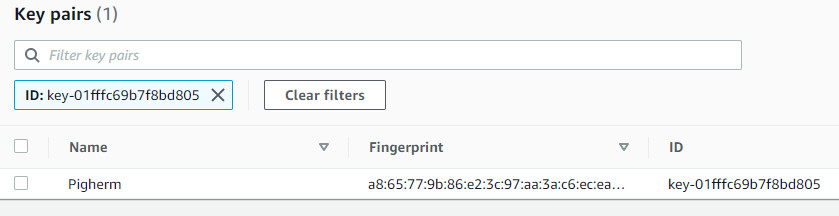
Bước 8 Xác nhận file Key Pair
3 Thiết lập Hadoop Cluster trong AWS EMR
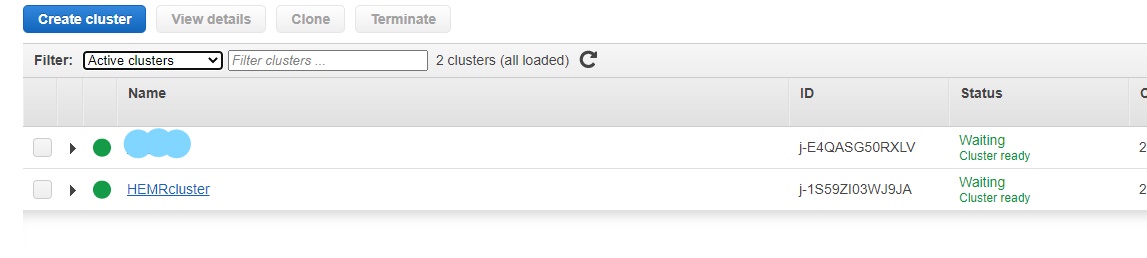
Bước 9 Chọn tạo Cluster
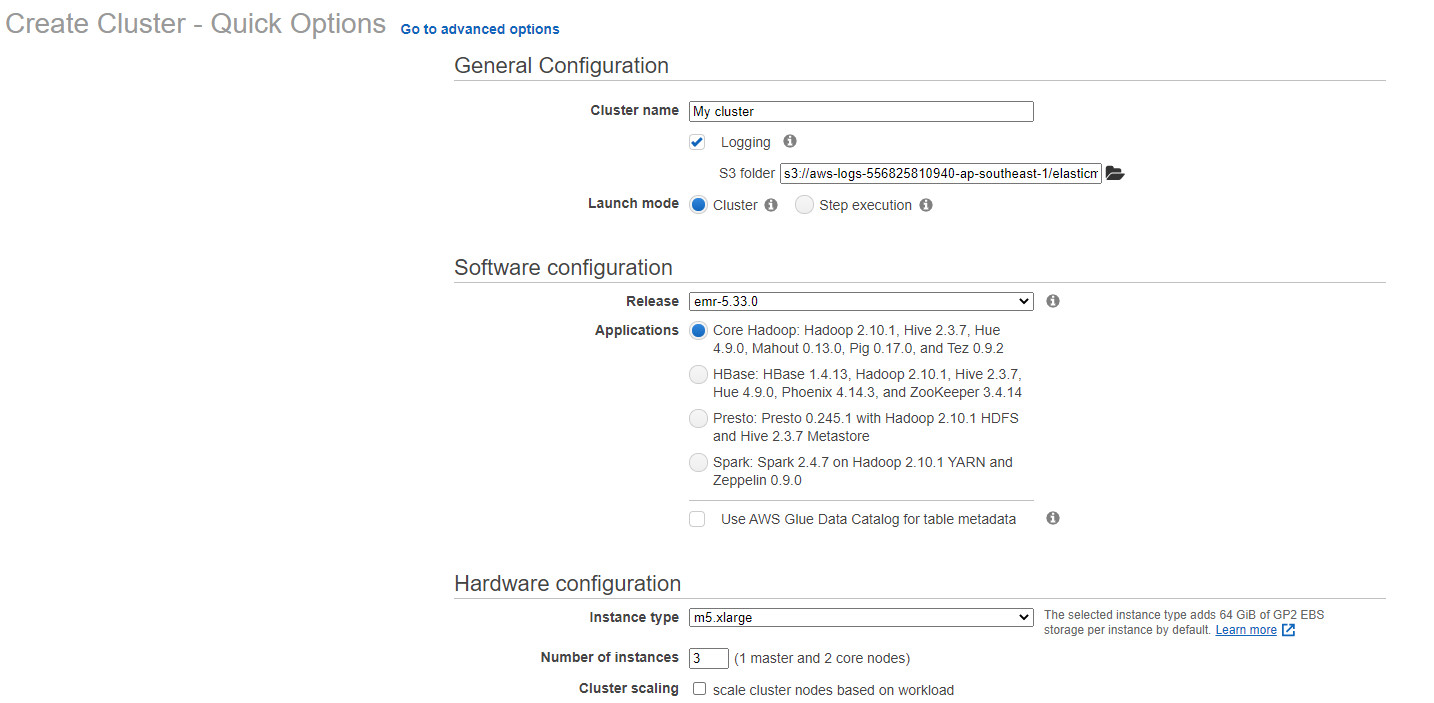
Bước 10 Chọn Go to Advanced options
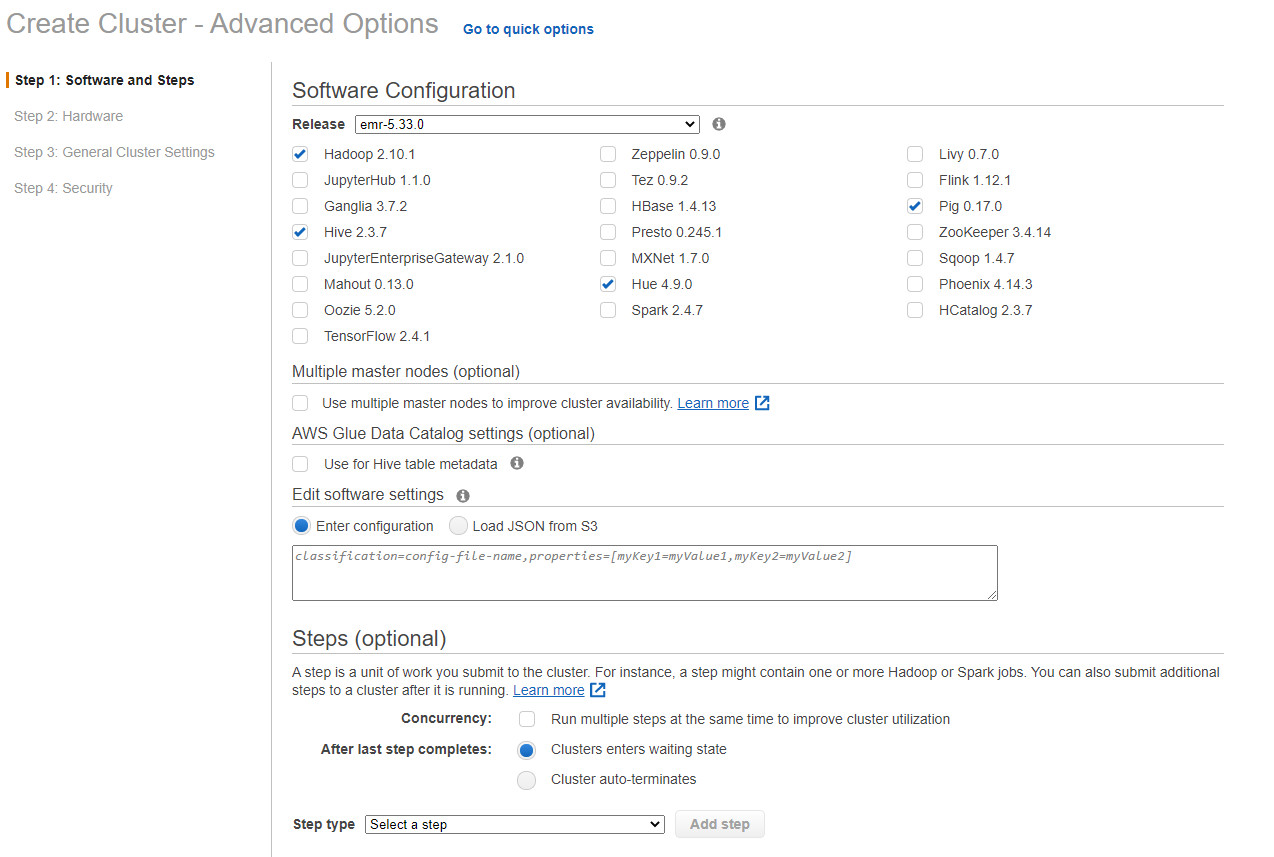
Bước 11 Thiết lập chọn phiên bản emr-5.33.0 sẽ ổn định hơn bản 6.xx.xx, chọn các phần mềm cần thiết. Chọn tiếp theo
Ở mục Multiple Master nodes, ta có thể tùy chỉnh để AWS tự động tạo ra một master node mới khi master nodes EC2 gặp vấn đề
Ở mục Step, ta có thể submit một tệp pig, hoặc hive để tự động cho cho Hadoop Cluster thực hiện 1 tác vụ đã được định nghĩa trước, ở bước này rất phù hợp cho nhu cầu sử dụng Hadoop Cluster chạy ETL Pipeline.
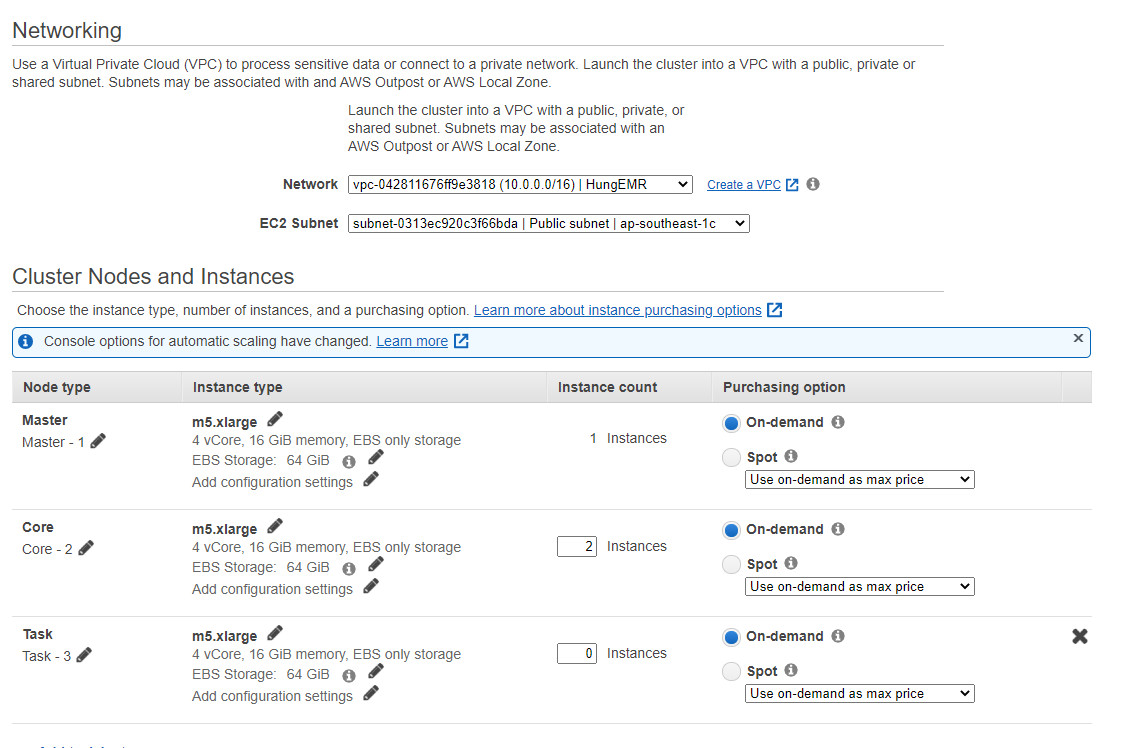
Bước 12. Chọn network là VPC đã tạo và các cấu hình của từng Master và Slave.
Tùy chỉnh cấu hình, lớp mạng của Hadoop Cluster tùy thuộc theo nhu cầu của doanh nghiệp/người dùng.
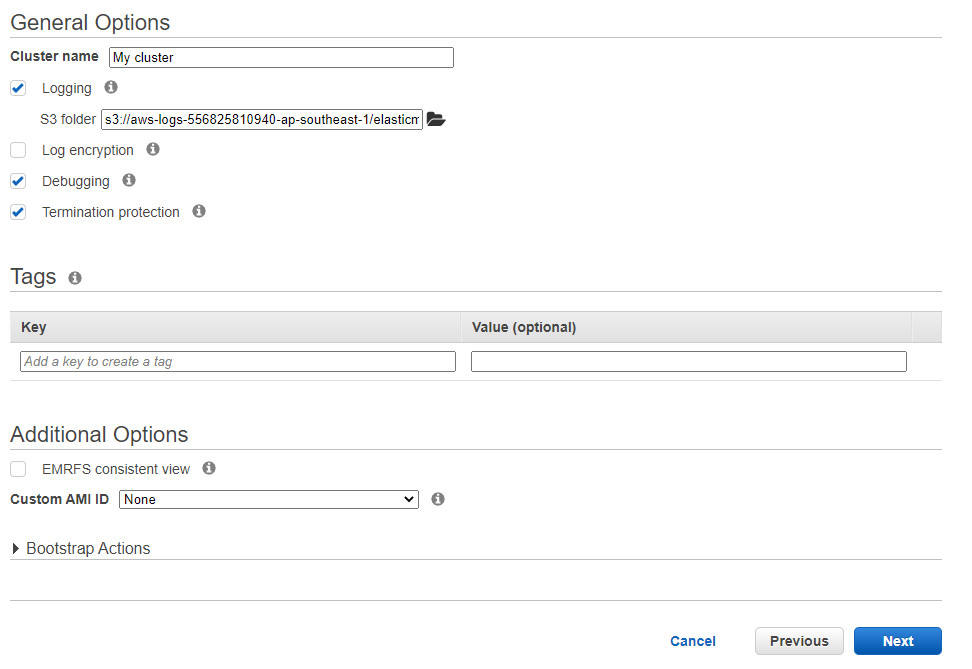
Bước 13 Đặt tên và trỏ đến địa chỉ file S3 bucket đã được tạo (có thể để default)
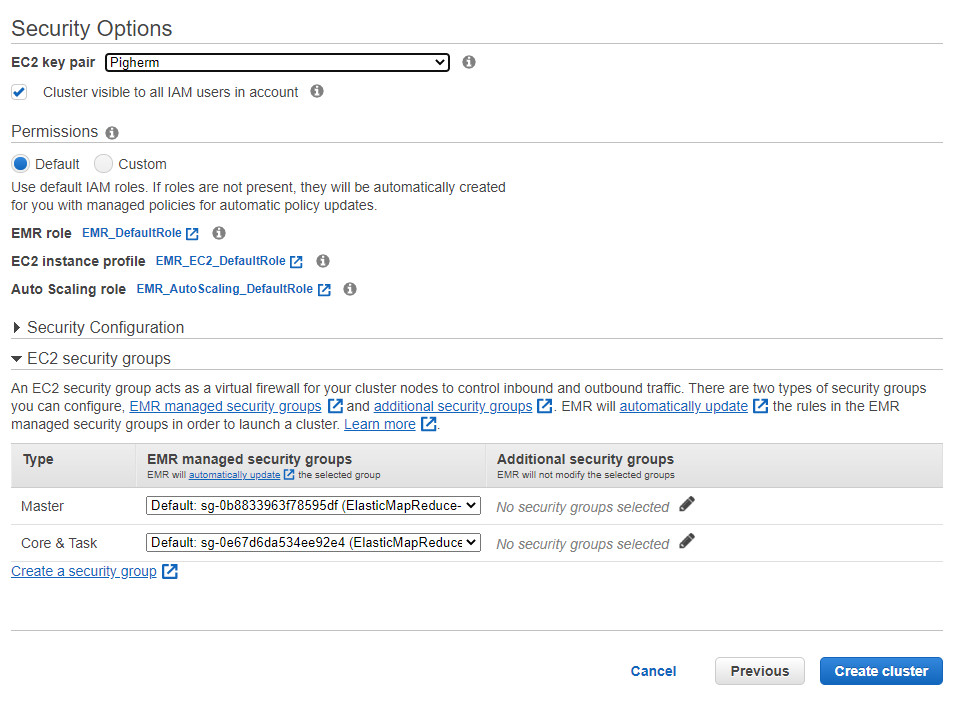
Bước 14 Chọn Key Pair đã tạo và AWS EMR sẽ tự động tạo các security group cho Master và Slave
4. Thiết lập cấu hình Security Group để có thể SSH vào từ địa chỉ IP cá nhân.
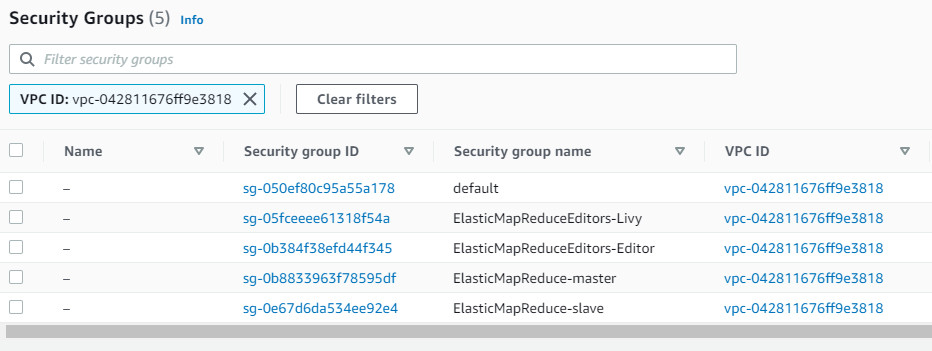
Bước 15 Chọn ElasticMapReduce-master
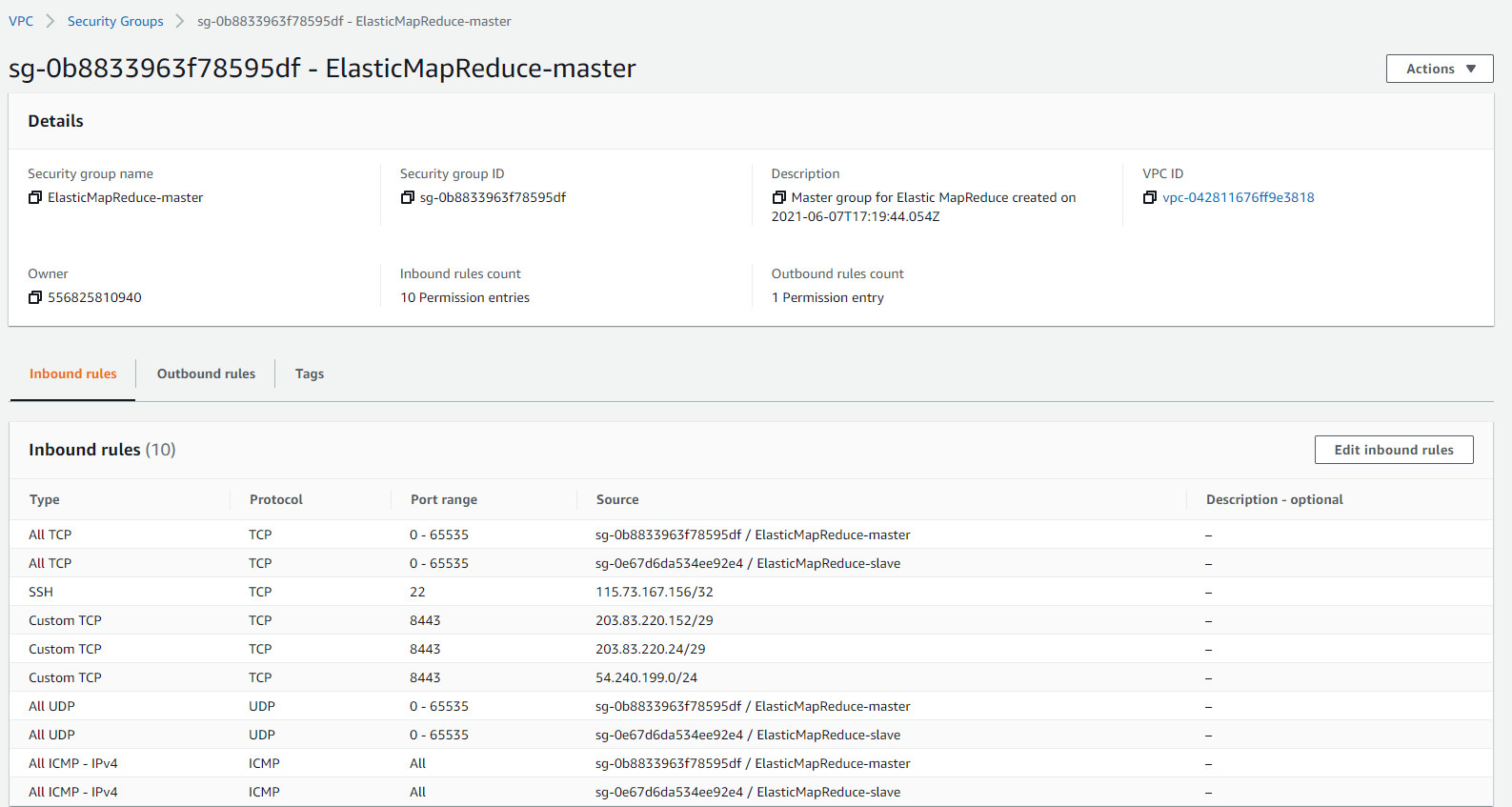
Bước 16 Edit Inbound Rules
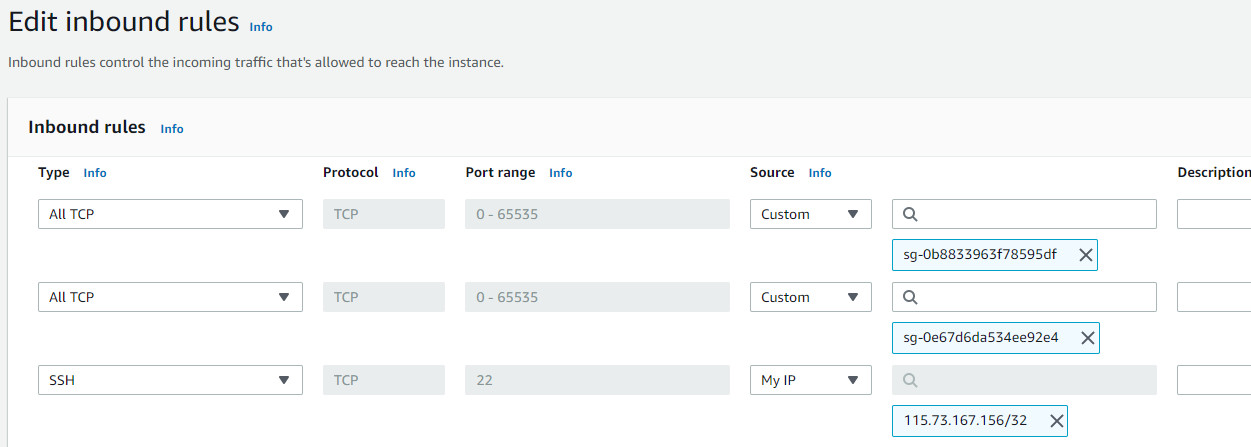
Bước 17 Thêm Type SSH và chọn source My IP.
5. SSH vào Hadoop Cluster: EC2 Master
Sử dụng phần mềm PuTTY để SSH vào EC2 Master
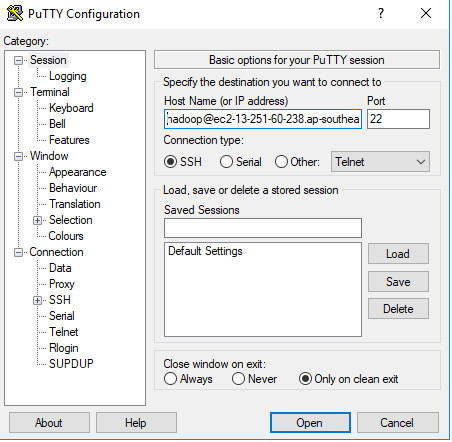
Bước 18 Điền Hostname vào bằng dns của EC2 Master
Bước 19 Chọn Key Pair để có thể truy cập vào EC2 Master (có thể tải xuống file key pair trong EC2)
Bước 20 Kết nối thành công.

Bước 21. Sử dụng các lệnh để tạo file pig latin.
Để tạo file: touch [File name].pig
Để truy cập vào file: vim [File name].pig
Để chạy pig: pig [File name].pig
4. Phân tích dữ liệu với Apache Pig
1.Phân tích từng loại beer được người dùng đánh giá tổng quát cao nhất và nồng độ cồn người dùng thích
Task1 – Code
–lấy dữ liệu gốc từ file csv
raw_data = LOAD ‘s3://demohungemr/BeerProject.csv’ using PigStorage(‘,’);
–tạo 1 bảng có cấu trúc 9 cột
structured_data = FOREACH raw_data GENERATE (float) $0 as beer_ABV, (int) $1 as beer_beerID, (int) $2 as beer_brewerID, $3 as beer_name, $4 as beer_style, (float) $5 as review_appearance, (float) $6 as review_palette, (float) $7 as review_overall, (float) $8 as review_taste, $9 as review_profileName;
–lọc dữ liệu trong bảng
filtered_data = FILTER structured_data BY review_overall is not null;
filtered_data = FILTER structured_data BY beer_ABV is not null;
filtered_data = FILTER structured_data BY beer_style is not null;
–chọn 100000 dòng đầu tiên trong bảng
filtered_data_limit = LIMIT filtered_data 100000;
–duyệt các thành phần trong filtered_data_limit sau đó sinh ra một bảng mới chứa các cột beer_ABV, beer_style, review_overall
A1 = FOREACH filtered_data GENERATE beer_ABV as beer_ABV, beer_style as beer_style, review_overall as review_overall;
–nhóm lại bảng theo beer_style
B1 = GROUP A1 by beer_style;
— đối với mỗi nhóm (beer_style), tìm dòng có tổng thể được đánh giá cao nhất, sắp xếp theo thứ tự giảm dần
C1 = FOREACH B1 {
I1 = ORDER A1 BY review_overall DESC;
— only take the row with max review_overall
J1 = LIMIT I1 5;
GENERATE group, J1.( beer_ABV, beer_style, review_overall);
};
— lưu trữ kết quả vào một folder
STORE C1 into ‘s3://demohungemr/task1_result.csv’ using PigStorage(‘,’);
File Pig latin: task1.pig
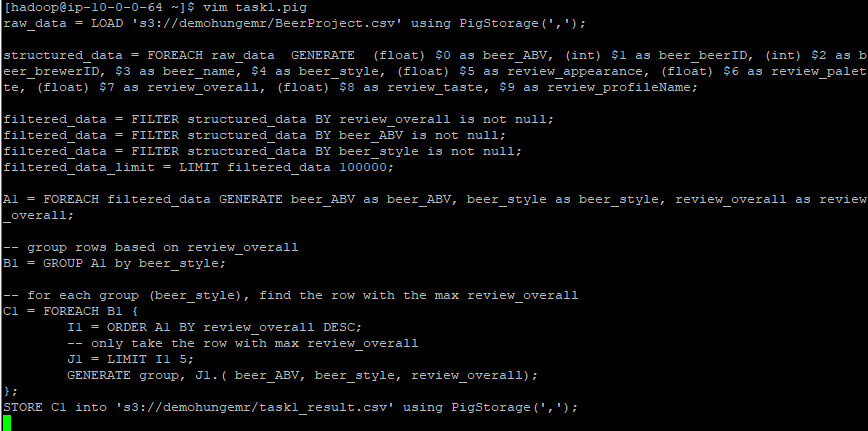
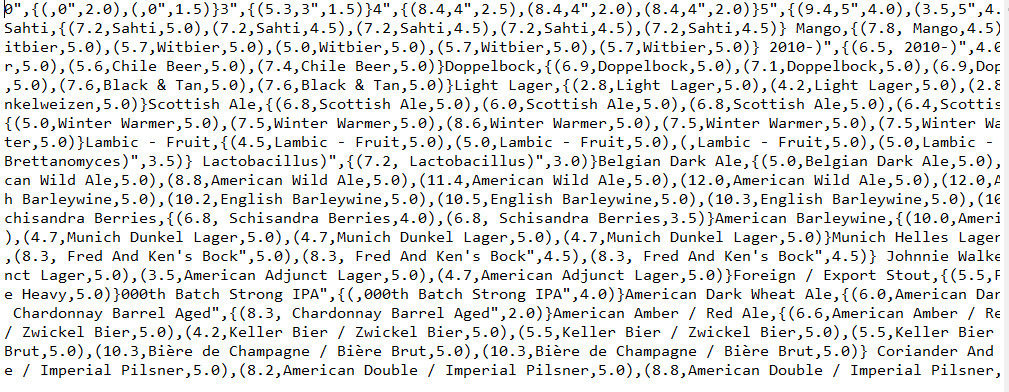
Kết quả:
2 Phân tích dữ liệu cho ra để vẽ histogram của các beerID theo được đánh giá từ 0-5
Task2 – Code
–lấy dữ liệu gốc từ file csv
raw_data = LOAD ‘s3://demohungemr/BeerProject.csv’ using PigStorage(‘,’);
–tạo 1 bảng có cấu trúc 9 cột
structured_data = FOREACH raw_data GENERATE (float) $0 as beer_ABV, (int) $1 as beer_beerID, (int) $2 as beer_brewerID, $3 as beer_name, $4 as beer_style, (float) $5 as review_appearance, (float) $6 as review_palette, (float) $7 as review_overall, (float) $8 as review_taste, $9 as review_profileName;
–lọc dữ liệu trong bảng
filtered_data = FILTER structured_data BY review_overall is not null;
filtered_data = FILTER structured_data BY beer_beerID is not null;
–chọn 100000 dòng dữ liệu đầu tiên trong bảng
filtered_data_limit = LIMIT filtered_data 100000;
A2 = FOREACH filtered_data_limit GENERATE (int) review_overall as review_overall_bin, beer_beerID as beer_beerID;
— show 30 dòng của dữ liệu
A2_limit = LIMIT A2 30;
— nhóm lại bảng theo review_overall_bin
B2 = GROUP A2 by review_overall_bin;
— chỉ lấy 5 giá trị trong review_overall
B2_limit = LIMIT B2 5;
— đếm số lượng của beer_beerID và chỉ lấy các beer_beerID có giá trị khác nhau
C2 = foreach B2_limit {
unique_IDs = DISTINCT A2.beer_beerID;
generate group, COUNT(unique_IDs) as number_beer;
};
— lưu trữ kết quả vào một folder
STORE C2 into ‘s3://demohungemr/task2_result.csv’ using PigStorage(‘,’);
File pig latin: task2.pig
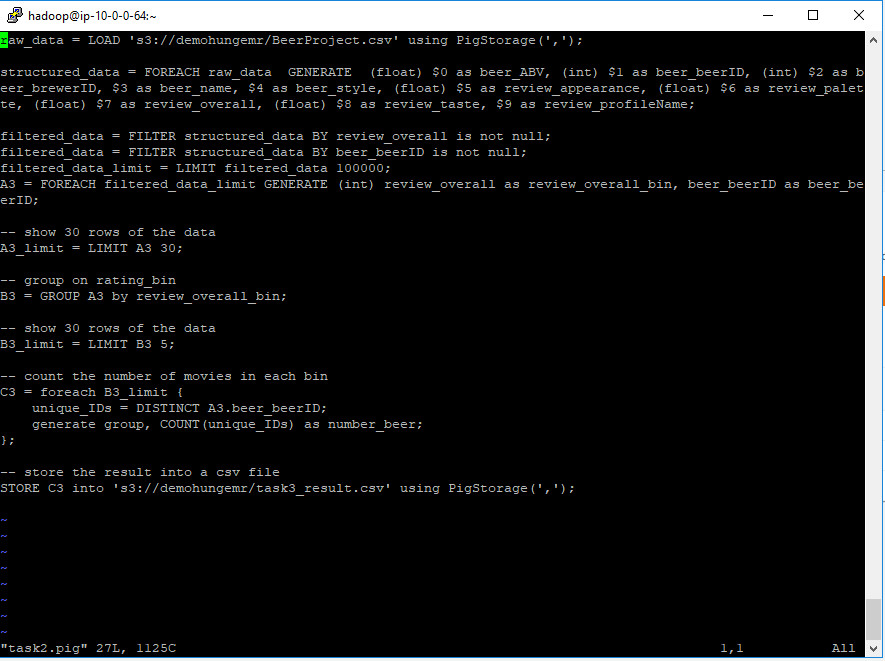
Kết quả:
![]()
3 Đếm từng loại beer style có bao nhiêu beer khác nhau
Task3 – Code
–lấy dữ liệu gốc từ file csv
raw_data = LOAD ‘s3://demohungemr/BeerProject.csv’ using PigStorage(‘,’);
–tạo 1 bảng có cấu trúc 9 cột
structured_data = FOREACH raw_data GENERATE (float) $0 as beer_ABV, (int) $1 as beer_beerID, (int) $2 as beer_brewerID, $3 as beer_name, $4 as beer_style, (float) $5 as review_appearance, (float) $6 as review_palette, (float) $7 as review_overall, (float) $8 as review_taste, $9 as review_profileName;
–lọc dữ liệu trong bảng
filtered_data = FILTER structured_data BY review_overall is not null;
filtered_data = FILTER structured_data BY beer_beerID is not null;
–chọn 100000 dòng đầu tiên trong bảng
filtered_data_limit = LIMIT filtered_data 100000;
— duyệt các thành phần trong filtered_data_limit sau đó sinh ra một bảng mới chứa các cột beer_style có kiểu dữ liệu là chararray, beer_beerID
A3 = FOREACH filtered_data_limit GENERATE (chararray) beer_style as beer_style, beer_beerID as beer_beerID;
— group các dòng theo beer_style
B3 = GROUP A3 by beer_style;
— với mỗi beer_style, đếm số lượng của beerID và chỉ lấy ra các beer_beerID có ID khác nhau
C3 = FOREACH B3 {
beer_ids = DISTINCT A3. beer_beerID;
GENERATE group, COUNT(beer_ids) as number_beer;
};
— lưu trữ kết quả vào một folder
STORE C3 into ‘s3://demohungemr/task3’ using PigStorage(‘,’);
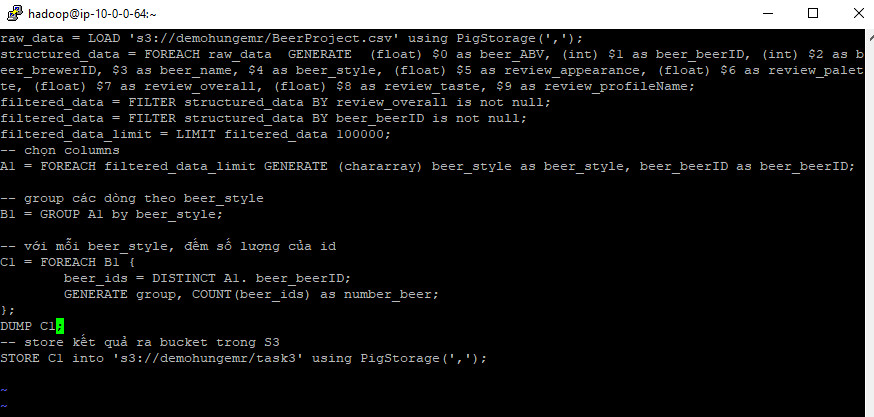
Và đây là kết quả:

Chân thành cảm ơn mọi người đã dành thời gian cho bài chia sẻ của Hùng Lê – Cloud Consultant tại Renova Cloud. Mong bạn đã nhận được nhiều hữu ích từ bài viết này và đón chờ bài viết theo về Machine Learning bằng PySpark với AWS EMR nhé.
Hãy theo dõi Renova Cloud ngay để được cập nhật những thông tin mới nhất!
Tác giả: Hùng Lê – Cloud Consultant tại Renova Cloud