Cloud Serverless Cơ Bản

Samira Kabbour
CMO
Chia sẻ bài viết
Sự hiểu biết cơ bản về điện toán serverless (điện toán không dùng Server) trên nền điện toán đám mây ngày càng trở nên quan trọng khi công nghệ này đã phát triển và hoàn thiện trong những năm gần đây, ngày càng trở nên phổ biến. Một số nhận định cho rằng chúng ta đang sống trong thời kỳ “hậu container”. Và thực tế cho thấy, serverless thực sự là một công nghệ hữu ích có thể cung cấp những lợi ích to lớn cho các lập trình viên và tổ chức.
Công nghệ ảo hóa (Virtualization) truyền thống cung cấp sự trừu tượng hóa và tối ưu hóa phần cứng, Containers làm việc này với hệ điều hành, còn Serverless thì thực hiện trên các môi trường runtime. Nghĩa là các lập trình viên không còn phải suy nghĩ đến các tài nguyên của server khi xây dựng và triển khai ứng dụng, cho phép họ có thể tập trung vào việc tạo dựng giá trị ứng dụng hơn là dành thời gian cho các hoạt động quản lý tài nguyên.
Biểu đồ bên dưới cho thấy trách nhiệm của người sử dụng khi dùng các mô hình dịch vụ Cloud như Infrastructure as a Service (IaaS), Container as a Service (CaaS) and Functions as a Service (FaaS).

Điều tuyệt vời của Serverless là nó cung cấp chức năng cho việc xử lý dữ liệu code của bạn bằng cách sử dụng nhiều ngôn ngữ lập trình khác nhau. Bạn chỉ cần đơn giản tải code của mình lên và nó sẽ nằm ở đó chờ cho đến khi được thực thi. Đặc biệt là bạn chỉ cần chi trả cho những gì mình sử dụng (Ví dụ như thời gian điện toán xử lý code cho bạn) và các fchức năng này có thể dễ dàng mở rộng khi cần.
Tất nhiên là vẫn có Server thực hiện phần xử lý code này cho mình, tuy nhiên những server này hoàn toàn được quản lý bởi các Nhà cung cấp dịch vụ Cloud và hoàn toàn trong suốt với người dùng. Lưu ý là cũng có những dạng điện toán Serverless truyền thống khác với những functions mà ta kể đến ở đây, trong bài viết này chỉ tập trung vào functions.
Những lợi ích chính của Serverless bao gồm:
- Không có server để quản lý
- Khởi tạo code nhanh
- Tính mở rộng liên tục
- Chỉ chi trả những gì mình sử dụng
- Hoàn toàn linh động
- Lý tưởng cho kiến trúc microservices
- Khả năng linh động truy cập vào nhiều tài nguyên đám mây khác
Trường hợp sử dụng Serverless phổ biến bao gồm việc thực hiện xử lý dữ liệu thời gian thực cho nhiều kiểu ứng dụng, xây dựng dịch vụ back-end với tính mở rộng cao hoặc có thể tự động mở rộng, và liên kết các hệ thống thành một chuỗi tích hợp các dịch vụ, ứng dụng và quy trình.
Thực sự quan trọng để hiểu rằng Serverless không phải lúc nào cũng thích hợp cho mọi tình huống. Trường hợp sử dụng thích hợp nhất thường là cho các ứng dụng mới, thuần trên kiến trúc nền Cloud với thường yêu cầu tính linh hoạt, và cho các kiến trúc microservices.
Serverless không thích hợp sử dụng cho các ứng dụng lâu đời không có tính linh hoạt, và được xây dựng trên sự độc lập về mặt ứng dụng. Trong một số trường hợp, nó có thể ẩn chứa chi phí ngầm và có thể có những vấn đề mặt bảo mật và quy chuẩn cần được xem xét.
Khi Serverless functions được cung cấp dưới dạng dịch vụ bởi nhà cung cấp dịch vụ Cloud Public, nó thường được gọi là Functions as a Service (FaaS). AWS Lambda là một trong những FaaS nổi tiếng nhất trong lĩnh vực.
AWS Lambda
AWS Lambda là một trong những serverless đầu tiên được đưa ra thị trường công nghệ ứng dụng trên nền Public Cloud và có một lượng người dùng lớn nhất hiện nay. Lambda hỗ trợ Java, Go, PowerShell, Node.js, C#, Python và Ruby, và cung cấp Runtime API giúp cho bạn có thể sử dụng bất cứ ngôn ngữ lập trình nào kèm theo khi xây dựng function cho mình.
Mỗi AWS Lambda function chạy trên môi trường độc lập của riêng nó, với những tài nguyên và hệ thống file riêng, code được lưu trữ thông qua dịch vụ Amazon S3 và được mã hóa. Mặc dù có một cơ chế an toàn mặc định loại bỏ bớt khi có một lượng lớn functions thực thi tại cùng một thời điểm, nhưng trên lý thuyết bạn có thể chạy function với một số lượng không giới hạn.
Lambda thực thi tác vụ thông qua tín hiệu được kích hoạt từ một sự kiện được thiết lập. Sự kiện này có thể đến từ các dịch vụ khác của AWS hoặc từ ứng dụng được tạo ra bởi lập trình viên. Dịch vụ hay ứng dụng này có khả năng tạo ra các sự kiện để kích hoạt một Lambda function. Lấy ví dụ, S3 có thể kích hoạt Lambda thực thi một function khi có dữ liệu được tải lên S3.
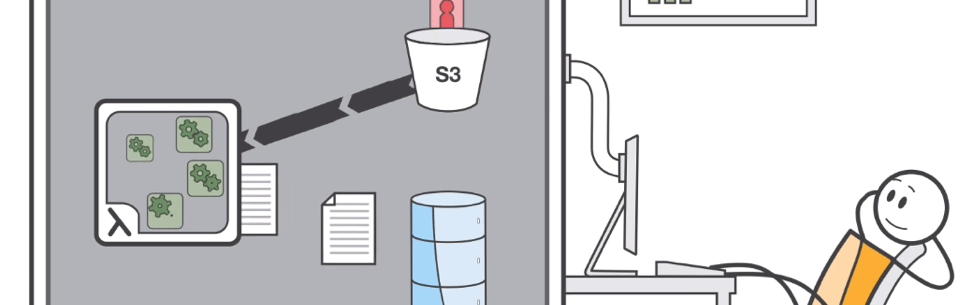
Hình bên dưới cho thấy khi một file hình ảnh được tải lên Amazon S3, sẽ kích hoạt một Lambda function để thay đổi kích thước của những hình ảnh này thành nhiều kích cỡ cho nhiều loại thiết bị khác nhau, và sau đó mới lưu trữ.

Như có nhắc đến trước đó, Serverless function không chỉ là một dạng điện toán không cần server, AWS (và các nhà cung cấp khác) có đưa ra các dạng dịch vụ điện toán được quản lý tương tự mà không cần người dùng phải quản lý các hệ điều hành bên dưới. Bao gồm:
- AWS Fargate (containers)
- Amazon Simple Storage Service (S3)
- Amazon DynamoDB (NoSQL DB)
- Amazon API Gateway