

Greenfeed
Greenfeed – giải pháp tối ưu hóa dữ liệu với AWS
Được thành lập năm 2003, sứ mệnh của Greenfeed là đem đến cho người tiêu dùng chuỗi thực phẩm sạch từ trang trại đến tận bàn ăn với quy trình

Công nghiệp
Công nghệ
TỔNG QUAN
Greenfeed – giải pháp tối ưu hóa dữ liệu với AWS
Được thành lập năm 2003, sứ mệnh của Greenfeed là đem đến cho người tiêu dùng chuỗi thực phẩm sạch từ trang trại đến tận bàn ăn với quy trình 3F Plus – FARM FEED FOOD. Trong quá trình vận hành quy trình khép kín đó, Renova Cloud rất vinh hạnh được hợp tác và đồng hành cùng Greenfeed trong lĩnh vực điện toán đám mây.
THÁCH THỨC CHÍNH
Trước đây để tổng hợp được các báo cáo sales hàng ngày (daily sales report), GreenFeed sử dụng các mẫu báo cáo trên file excel và thu thập thông tin từ nhiều nguồn dữ liệu khác nhau như: hệ thống SAP, hệ thống Solomon ERP tại các nhà máy Việt Nam, Lào, Campuchia, Myanmar; và cả dữ liệu từ nhiều file excel khác nhau.
Do các dữ liệu này đang bị phân tán tại nhiều nơi, và do các bộ phận khác nhau quản lý, để tổng hợp thông tin và tạo ra một báo cáo hợp nhất sẽ mất nhiều thời gian và phải thực hiện thủ công qua nhiều giai đoạn.
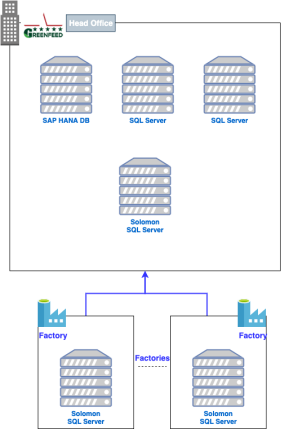
Khi dữ liệu trở thành một trong những tài sản lớn nhất và có giá trị nhất của doanh nghiệp như một xu thế không thể đảo ngược, cách thức lưu trữ dữ liệu và phân tích dữ liệu có thể ảnh hưởng đến các quyết định trong kinh doanh. Các công cụ báo cáo BI (business intelligence) và phân tích nâng cao là nền tảng mà các tổ chức đang áp dụng để thúc đẩy doanh nghiệp phát triển trong nền kinh tế đầy cạnh tranh hiện nay. Do đó GF đã đưa ra các yêu cầu như sau:
- Xây dựng 01 nguồn dữ liệu tập trung (data lake), nơi có thể lưu trữ toàn bộ dữ liệu từ tất cả nguồn khác nhau để phục vụ mục đích báo cáco hiện tại: hệ thống SAP, Solomon, Excel files.
- Xây dựng một giải pháp báo cáo tự động, mỗi ngày sẽ tự cập nhật dữ liệu mới nhất và tạo ra các báo cáo daily sales. Ban giám đốc và người dùng sẽ truy cập qua web portal hoặc mobile để xem các báo cáo.
- Data lake có năng lực mở rộng không giới hạn, và có thể lưu trữ thêm các nguồn dữ liệu khác nhau trong tương lai như các database khác, nguồn dữ liệu từ bên ngoài (của đối tác, các mạng xã hội),…
GIẢI PHÁP
Giải pháp đưa ra nhằm trả lời những câu hỏi then chốt sau:
- Làm thế nào để chúng ta có thể trích xuất dữ liệu từ nguồn SAP?
- Làm thế nào để chúng ta có thể trích xuất dữ liệu từ nguồn Solomon với cả các site nước ngoài?
- Nguồn dữ liệu từ Excel sẽ ảnh hưởng như thế nào?
- Làm sao để chúng ta có thể tự động hóa quy trình này?
- Và làm sao để các giải pháp tương thích với AWS để khách hàng dễ dàng sử dụng?
Đầu tiên, để có thể trích xuất dữ liệu từ các nguồn về AWS, chúng ta cần thiết lập một đường kết nối bảo mật vì sử dụng kết nối Internet thông thường sẽ không đảm bảo tính bảo mật. Vậy nên, giải pháp VPN Site to Site của AWS đã được sử dụng để có thể tạo các đường VPN thông mạng từ AWS xuống dưới văn phòng của GreenFeed, cũng như là ở các site nước ngoài.
Về việc trích xuất dữ liệu, chúng ta có thể nghĩ đến ngay dịch vụ AWS DMS (Database Migration Service) nhưng thật đáng tiếc là DMS không hỗ trợ phiên bản SAP và Solomon SQL Server mà GreenFeed đang sử dụng. Thế nên, chúng ta chỉ có thể tạo script để có thể trích xuất dữ liệu và Python sẽ là ngôn ngữ chính để chúng ta thực hiện việc này.
Đối với nguồn SAP, chúng ta tạo ra các ứng dụng bằng việc sử dụng SAM CLI. Với SAM CLI, chúng ta chỉ cần phải quan tâm đến khía cạnh lập trình, còn lại SAM sẽ triển khai chúng lên Lambda Function AWS. Với nguồn SAP, chúng ta sẽ chia ra 2 nguồn và trích xuất như sau:
- Dữ liệu dành cho Dimension Table
-
- Đối với các dữ liệu dành cho Dimension, chúng ta sẽ thực hiện call Odata API của SAP để đẩu dữ liệu hoàn toàn vào trong S3 dưới định dạng tệp csv rồi tiến hành sao chép dữ liệu từ S3 vào trong Redshift.
-
- Dữ liệu dành cho Fact Table
-
- Đối với dữ liệu dành cho Fact Table, chúng ta cũng sẽ call Odata API của SAP để load dữ liệu lịch sử lên trước, sau đó thực hiện bước đẩy dữ liệu dần dần hằng ngày và để vào trong S3. Từ S3 chúng ta cũng tiền hành sao chép dữ liệu vào trong Redshift.
-
Đối với nguồn Solomon, chúng ta cũng thực hiện một Python Script để trích xuất dữ liệu và để vào trong S3. Do dữ liệu Solomon khá nhỏ nên chúng ta có thể sử dụng Redshift Spectrum để truy vấn dữ liệu từ trong Redshift ra ngoài S3 mà không phải đẩy dữ liệu từ S3 vào trong Redshift. Để thuận tiện hơn trong việc truy vấn, chúng ta sẽ có một Glue Job để có thể tinh chỉnh lại Struct Type của toàn bộ bảng và chuyển đổi về định dạng Parquet.
Đối với Excel, chúng ta upload thẳng lên S3 và load vào Redshift dùng câu lệnh COPY.
Tiếp đến sẽ là việc tự động hóa các bước trên:
- Đối với SAP, chúng ta sẽ đặt các tính năng Lambda được tạo từ SAM CLI vào trong một Step Function cho từng loại dữ liệu: dữ liệu cho Dimension, dữ liệu cho Fact. Đối với dữ liệuFact, Step Function sẽ có thêm một bước là lấy ngày hiện tại và chạy một quy trình được thiết kế sẵn để load dữ liệu vào Redshift một cách dần dần. Với dữ liệu Dimension, Step Function sẽ thực hiện việc đẩy dữ liệu hoàn toàn vào trong S3 và sau đó Evenbridge sẽ trigger truy vấn chạy quy trình để load các dữ liệu Dimension vào trong Redshift
- Đối với Solomon SQL Server, script được đặt trong một EC2 server, thế nên chúng ta sẽ sử dụng Window Scheduler để có thể đặt lịch chạy cho công việc trích xuất dữ liệu. Sau đó, bản thân AWS Glue có thể tự đặt lịch để chuyển đổi về parquet với các dữ liệu mới.
- Đối với Excel, chúng ta cũng sử dụng Eventbridge để trigger các quy trình load dữ liệu vào trong Redshift.
- Sau khi dữ liệu từ các nguồn đã được load vào trong Redshift, chúng ta sẽ trigger các quy trình này để load dữ liệu từ Staging của Redshift vào trong Datawarehouse.

LỢI ÍCH
- Hệ thống datalake/data warehouse trên AWS và các báo cáo trên nền tảng Power BI đã mang lại các lợi ích lớn cho GF như sau:
- Một hệ thống datalake có thể năng lưu trữ toàn bộ dữ liệu có cấu trúc và không cấu trúc. Các dịch vụ/ công cụ hỗ trợ của AWS sẽ giúp GF dễ dàng ETL các nguồn dữ liệu khác nhau về datalake.
- Dễ dàng xem các báo cáo BI đã được tự động hoá. Các quy trình ETL dữ liệu đã được thiết lập tự động hàng ngày đổ về datalake, sau đó Power BI sẽ tự động kết nối và xây dựng nên các báo cáo daily sales theo yêu cầu của GF (hình bên dưới là một ví dụ về báo cáo sales trên giao diện mobile)
- Khả năng mở rộng của hệ thống datalake hoàn toàn có thể đáp ứng thêm các yêu cầu về phân tích nâng cao trong tương lai của GF, cũng như áp dụng các công nghệ AI/ML để đưa ra các báo cáo và quyết định quan trọng của doanh nghiệp trong hoạt động kinh doanh.



