

Sự phát triển của kho dữ liệu ĐIỆN TOÁN đám mây VÀ dịch vụ nào dành cho bạn?

Doron Shachar
CEO & Founder
Chia sẻ bài viết
Mục lục
Với sự gia tăng nhu cầu phân tích dữ liệu, nhóm kỹ sư phân tích dữ liệu đa chức năng và đám mây, đã làm “Cloud Data Warehouse” nổi lên nhờ sự đáp ứng linh hoạt và đổi mới. Đám mây giúp dữ liệu dễ quản lý, tiếp cận hơn với nhiều người dùng. Và xử lý nhanh hơn rất nhiều bằng nhiều cách khác nhau.
Tuy nhiên, việc chọn kho dữ liệu đám mây phù hợp với nền tảng dữ liệu của bạn, không phải là việc dễ dàng.
Với việc cho ra mắt Amazon Redshift vào năm 2013. Sau đó là Snowflake, Google Big Query và những kho lưu trữ dữ liệu khác trong những năm tiếp theo. Thị trường đang ngày càng trở nên nóng bỏng hơn. Và Data Lakes càng làm cho việc chọn lựa cũng trở nên khó khăn hơn nhiều!
Cho dù bạn chỉ mới bắt đầu hay đang trong quá trình đánh giá lại giải pháp hiện có của mình. Sau đây là những điều bạn cần biết để chọn đúng Data Warehouse (hoặc Lake) cho việc lưu trữ dữ liệu:
Data Warehouse/Lake là gì?
Data Warehouse và Lake là nền tảng của cơ sở hạ tầng dữ liệu. Cung cấp khả năng lưu trữ, sức mạnh tính toán và thông tin theo ngữ cảnh trong hệ sinh thái của bạn. Giống như động cơ của ô tô, chúng như những chú ngựa kéo theo các nền tảng dữ liệu.
Các Data Warehouse và Lake kết hợp bốn thành phần chính sau:
Metadata
Các Data Warehouse và Lake cung cấp dịch vụ để quản lý và theo dõi tất cả các cơ sở dữ liệu, schema và bảng mà bạn tạo. Các đối tượng này đi kèm với thông tin bổ sung như schema, kiểu dữ liệu, mô tả do người dùng tạo hoặc thậm chí là các thống kê khác về dữ liệu.
Kho lưu trữ
Lưu trữ: Warehouse/Lake lưu trữ vật lý tất cả các bản ghi trên tất cả các bảng.
Điện toán
Warehouse/Lake thực thi trên các bản ghi dữ liệu mà nó lưu trữ. Đây là công cụ cho phép người dùng “truy vấn” dữ liệu, nhập dữ liệu, chuyển đổi dữ liệu – và rộng hơn là trích xuất giá trị từ nó. Thông thường, các phép tính này được thể hiện qua SQL.
Tại sao nên chọn Data Warehouse?
Data Warehouse là giải pháp được tích hợp và quản lý hoàn toàn. Giúp việc xây dựng và vận hành đơn giản hơn. Khi sử dụng Data Lakes, bạn thường sử dụng metadata, lưu trữ và tính toán từ một giải pháp duy nhất. Mà được xây dựng và vận hành bởi một nhà cung cấp duy nhất.
Không giống như Date Lakes, Data Warehouse thường yêu cầu nhiều cấu trúc và schema hơn. Điều này giúp phân tích dữ liệu tốt hơn nhưng ít phức tạp hơn khi đọc và sử dụng dữ liệu.
Nhờ các chức năng được đóng gói sẵn và hỗ trợ mạnh mẽ cho SQL. Data Warehouse tạo điều kiện thuận lợi cho việc truy vấn nhanh chóng. Khiến chúng trở nên tuyệt vời cho các nhóm kỹ sư phân tích dữ liệu.
Các Data Warehouse phổ biến bao gồm:
- Amazon Redshift: thuộc Amazon Web Services (AWS), kho dữ liệu đám mây phổ biến rộng rãi (và sẵn có) đầu tiên. Nó tận dụng kết nối nguồn để chuyển dữ liệu từ các nguồn dữ liệu thô vào lưu trữ quan hệ. Cấu trúc lưu trữ dạng cột và quá trình xử lý song song của Redshift khiến nó trở nên lý tưởng cho khối lượng công việc phân tích.
- Google BigQuery: Giống như Redshift, Google BigQuery tận dụng nền tảng đám mây độc quyền của công ty mẹ (Google Cloud). Sử dụng định dạng lưu trữ dạng cột và tận dụng quá trình xử lý song song để truy vấn nhanh. Không giống như Redshift, BigQuery là một giải pháp không máy chủ có quy mô linh hoạt theo nhu cầu.
- Snowflake: Không giống như Redshift hoặc GCP dựa vào các đám mây độc quyền của họ để hoạt động. Khả năng lưu trữ dữ liệu đám mây của Snowflake được cung cấp bởi AWS, Google, Azure và các hạ tầng đám mây công cộng khác. Không giống như Redshift, Snowflake cho phép người dùng trả phí tính toán và lưu trữ riêng biệt. Làm cho Data Warehouse trở thành một lựa chọn tuyệt vời cho các nhóm đang tìm kiếm dạng chi trả linh hoạt hơn.
Tại sao nên chọn Data Lake?
Các Data Lake là phiên bản thủ công của Data Warehouse. Cho phép các nhóm kỹ thuật dữ liệu lựa chọn các công nghệ siêu dữ liệu, lưu trữ và tính toán khác nhau mà họ muốn sử dụng tùy thuộc vào nhu cầu hệ thống.
Các Data Lake sẽ lý tưởng cho các nhóm đang tìm cách xây dựng một nền tảng tùy chỉnh, thường được hỗ trợ bởi một số ít (hoặc nhiều) kỹ sư dữ liệu.
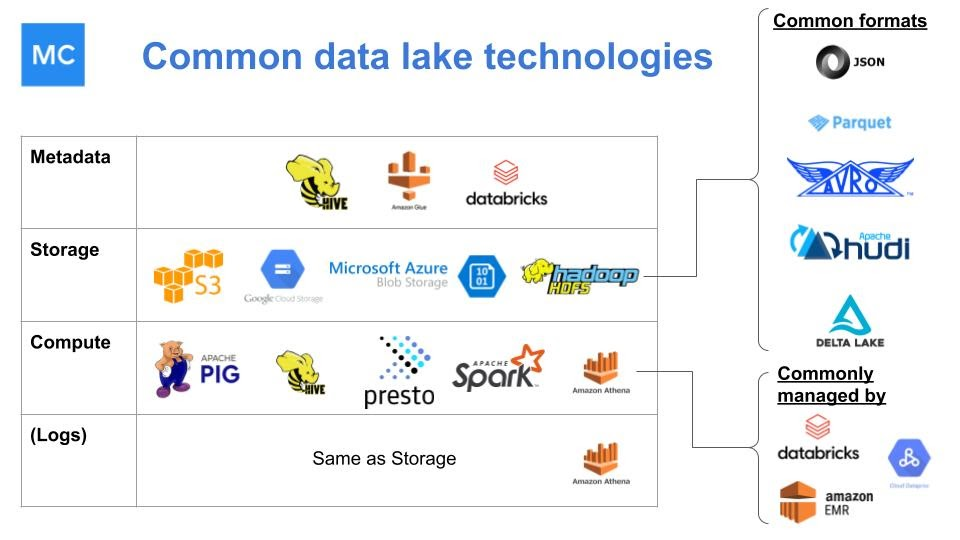
Các Data Lake thường được xây dựng với sự kết hợp của công nghệ mã nguồn mở và mã nguồn đóng, giúp chúng dễ dàng tùy chỉnh và có thể xử lý các quy trình công việc ngày càng phức tạp. Hình ảnh do Lior Gavish / Monte Carlo cung cấp.
Một số đặc điểm chung của hồ dữ liệu bao gồm:
- Tính toán và lưu trữ tách rời: Chức năng này không chỉ có thể cho phép tiết kiệm đáng kể chi phí. Mà còn tạo điều kiện thuận lợi cho việc phân tích cú pháp. Và làm phong phú dữ liệu để truyền phát và truy vấn theo thời gian thực.
- Hỗ trợ mạnh mẽ cho điện toán phân tán: Điện toán phân tán hỗ trợ mạnh mẽ xử lý dữ liệu quy mô lớn. Vì nó cho phép hiệu suất truy vấn phân đoạn tốt hơn. Thiết kế có khả năng chịu lỗi cao hơn và xử lý dữ liệu song song vượt trội.
- Khả năng tùy chỉnh và tương tác: Do tính chất “cắm và chạy”, các data lake hỗ trợ khả năng mở rộng dễ dàng nhờ vào sự kết nối linh hoạt các phần tử khác nhau của kho lưu trữ. Cũng như nhu cầu dữ liệu của công ty khi phát triển và mở rộng.
- Được xây dựng rộng rãi trên mã nguồn mở: Điều này tạo điều kiện giảm thiểu tình trạng khóa từ nhà cung cấp. Và cung cấp khả năng tùy chỉnh tuyệt vời, hoạt động tốt.
- Khả năng xử lý dữ liệu không có cấu trúc hoặc có cấu trúc yếu: Các Data Lake và một số Data Warehouse (như Snowflake và BigQuery) có thể hỗ trợ dữ liệu thô. Có nghĩa là bạn có tính linh hoạt cao hơn khi làm việc với dữ liệu của mình, lý tưởng cho các nhà khoa học dữ liệu và kỹ sư dữ liệu. Làm việc với dữ liệu thô cho phép bạn kiểm soát nhiều hơn dữ liệu tổng hợp và tính toán của mình.
- Hỗ trợ các mô hình lập trình non-SQL phức tạp: Nhiều Data Lake hỗ trợ Apache Hadoop, Apache Spark, PySpark. Và các framework khác dành cho khoa học dữ liệu nâng cao và machine learning.
Nhiều kho dữ liệu, chẳng hạn như Snowflake và BigQuery, hiện cũng hỗ trợ một số chức năng này.
Ngay khi bạn nghĩ rằng quyết định này đã đủ khó khăn rồi thì một tùy chọn lưu trữ dữ liệu khác lại nổi lên như một lựa chọn ngày càng phổ biến, đặc biệt là trong các nhóm kỹ thuật dữ liệu.
Chẳng hạn như Data Lakehouse, giải pháp kết hợp các tính năng của cả Data Warehouse và Data Lake. Và kết quả là, kết hợp các công nghệ phân tích dữ liệu truyền thống với những công nghệ được xây dựng cho các tính toán nâng cao hơn (như là cho machine learning).

Data Lakehouse cung cấp khả năng tùy chỉnh cao hơn nữa. Cho phép các nhóm kỹ sư lưu trữ dữ liệu trên đám mây. Và chỉ cần tận dụng một warehouse cho việc tính toán. Hình ảnh do Lior Gavish / Monte Carlo cung cấp.
Các Data Lakehouse lần đầu tiên xuất hiện khi các nhà cung cấp giới thiệu tính năng vô cùng hữu ích “lake-style”. Chẳng hạn như Redshift Spectrum hoặc Delta Lake. Tương tự, các Data Lake đã và đang bổ sung các công nghệ như SQL chức năng và schema.
Ngày nay, sự cách biệt giữa Warehouse và Lake ngày càng dần thu hẹp. Giúp có thể truy cập các tính nắng tốt nhất của cả hai từ một dịch vụ.
Các chức năng sau đang giúp các cơ sở dữ liệu làm mờ ranh giới giữa hai công nghệ:
- SQL hiệu suất cao: các công nghệ như Presto và Spark cung cấp cho SQL khả năng tương tác tốc độ trên các data lake. Điều này mở ra khả năng các data lake có thể phân tích và làm việc trực tiếp. Mà không yêu cầu ETL vào kho dữ liệu truyền thống.
- Schema: các định dạng tệp như Parquet giới thiệu schema tốt hơn cho các bảng dữ liệu, cũng như định dạng cột để có hiệu quả truy vấn cao hơn.
- Tính nguyên tử, nhất quán, cô lập và độ bền (ACID): các công nghệ Lake như Delta Lake và Apache Hudi giới thiệu khả năng ghi/đọc với độ tin cậy cao. Và đưa Lake tiến lên một bước gần hơn với các thuộc tính ACID. Mà là tiêu chuẩn trong các công nghệ cơ sở dữ liệu truyền thống.
- Dịch vụ được quản lý: đối với các nhóm muốn giảm bớt tác vụ xây dựng và vận hành Data Lake, đã có nhiều dịch vụ Lake được quản lý ra đời. Ví dụ: Databricks cung cấp phiên bản được quản lý Apache Hive, Delta Lake, và Apache Spark. Trong khi Amazon Athena cung cấp công cụ truy vấn SQL Lake được quản lý hoàn toàn và Amazon’s Glue cung cấp dịch vụ siêu dữ liệu được quản lý hoàn toàn.
Với sự gia tăng của tính năng tổng hợp và phát trực tuyến dữ liệu theo thời gian thực để cung cấp thông tin phân tích tốc độ ánh sáng (tốc độ Thung lũng Silicon: Uber, DoorDash, và Airbnb), các Data Lakehouse có thể sẽ trở nên phổ biến và đáp ứng các nhóm dữ liệu trong nhiều ngành trong những năm tới.
Vậy, dịch vụ nào dành cho bạn?
Điều này thật không dễ dàng. Trên thực tế, không có gì ngạc nhiên khi các kỹ sư thường xuyên di chuyển từ giải pháp kho dữ liệu này sang giải pháp kho dữ liệu khác khi nhu cầu của tổ chức dữ liệu của họ thay đổi và phát triển. Để đáp ứng nhu cầu của người tiêu dùng dữ liệu (mà ngày nay, gần như mọi bộ phận trong doanh nghiệp, từ Tiếp thị và Bán hàng cho Hoạt động và Nhân sự cần đến).
Trong khi các Data Warehouse thường phù hợp cho các nền tảng dữ liệu để phân tích và báo cáo dữ liệu. Các Data Lake ngày càng trở nên thân thiện với người dùng.
Bất kể con đường bạn chọn là gì, hãy áp dụng các phương pháp sau:
Chọn giải pháp phù hợp với mục tiêu dữ liệu của công ty bạn.
Nếu công ty chỉ thường xuyên sử dụng một hoặc hai nguồn dữ liệu quan trọng cho một vài quy trình công việc được chọn. Thì việc xây dựng một Data Lake từ đầu có thể không hợp lý, cả về thời gian và tài nguyên. Nhưng nếu công ty muốn rõ ràng chi tiết mọi thứ, thì giải pháp hybrid warehouse-lake có thể giúp tổng hợp chi tiết nhanh chóng, chi tiết cho từng người dùng trên các vai trò khác nhau.
Biết người dùng là ai.
Liệu người dùng chính của nền tảng dữ liệu của bạn là nhóm phân tích kinh doanh, được phân bổ trên một số chức năng khác nhau không? Còn về một đội ngũ kỹ sư dữ liệu chuyên dụng thì sao? Hay một vài nhóm nhà khoa học dữ liệu đang chạy thử nghiệm A / B với nhiều bộ dữ liệu khác nhau? Tất cả những điều trên? Bất kể, hãy tùy chọn Data Warehouse/Lake/Lakehouse phù hợp với các bộ kỹ năng và nhu cầu của người dùng.
Đừng quên khả năng quản lý dữ liệu.
Data Warehouse, Data Lake, Data Lakehouse: Tất cả ba giải pháp (và bất kỳ sự kết hợp nào giữa chúng) sẽ yêu cầu một cách tiếp cận khác nhau để quản trị dữ liệu và chất lượng dữ liệu.
Rốt cuộc, nền tảng dữ liệu của bạn chỉ mạnh mẽ và đáng tin cậy nếu như dữ liệu nhập vào chính xác. Nếu dữ liệu của bạn bị hỏng, bị thiếu hoặc không chính xác, thì sử dụng dịch vụ có cao cấp đến mấy cũng không còn quan trọng nữa .
Đầu tư quá nhiều vào dịch vụ mới nhất và tốt nhất cũng sẽ không hiệu quả nếu dữ liệu không chính xác. Để giải quyết vấn đề này, một số nhóm kỹ sư đang tận dụng khả năng quan sát dữ liệu, một cách tiếp cận đầu cuối để giám sát và cảnh báo các vấn đề trong đường ống dữ liệu của bạn.
Hãy cùng chúng tôi tìm hiểu thêm về điều này trong bài viết sắp tới.
Tác giả: Doron Shachar, CEO Renova Cloud


