

THE RISE OF CLOUD DATA WAREHOUSE

Quang Tran
CCO
Share article
Table of Contents
The rise of data-driven analytics, cross-functional data teams, and most importantly, the cloud, the phrase “cloud data warehouse” is nearly analogous with agility and innovation. In many ways, the cloud makes data easier to manage, more accessible to a wider variety of users, and far faster to process.
When it comes to selecting the right cloud data warehouse for your data platform, however, the answer isn’t as straightforward. With the release of Amazon Redshift in 2013 followed by Snowflake, Google Big Query, and others in the subsequent years, the market has become increasingly hot. Add data lakes to the mix, and the decision becomes that much harder!
Whether you’re just getting started or are in the process of re-assessing your existing solution, here’s what you need to know to choose the right data warehouse (or lake) for your data stack:
What makes a data warehouse/lake?
Data warehouses and lakes are the foundation of your data infrastructure, providing the storage, compute power, and contextual information about the data in your ecosystem. Like the engine of a car, these technologies are the workhorse of the data platform.
Data warehouses and lakes incorporate the following four main components:
Metadata
Warehouses and lakes typically offer a way to manage and track all the databases, schemas, and tables that you create. These objects are often accompanied by additional information such as schema, data types, user-generated descriptions, or even freshness and other statistics about the data.
Storage
Storage refers to the way in which the warehouse/lake physically stores all the records that exist across all tables.
Compute
Compute refers to the way in which the warehouse/lake performs calculations on the data records it stores. This is the engine that allows users to “query” data, ingest data, transform it — and more broadly, extract value from it. Frequently, these calculations are expressed via SQL.
Why choose a data warehouse?
Data warehouses are fully integrated and managed solutions, making them simple to build and operate out-of-the-box. When using a data lake, you typically use metadata, storage and compute from a single solution, built and operated by a single vendor.
Unlike data lakes, data warehouses typically require more structure and schema, which often forces better data hygiene and results in less complexity when reading and consuming data.
Owing to its pre-packaged functionalities and strong support for SQL, data warehouses facilitate fast, actionable querying, making them great for data analytics teams.
Common data warehouse technologies include:
- Amazon Redshift: The first widely popular (and readily available) cloud data warehouse, Amazon Redshift sits on top of Amazon Web Services (AWS) and leverages source connectors to pipe data from raw data sources into relational storage. Redshift’s columnar storage structure and parallel processing makes it ideal for analytic workloads.
- Google BigQuery: Like Redshift, Google BigQuery leverages its mothership’s proprietary cloud platform (Google Cloud), uses a columnar storage format, and takes advantage of parallel processing for quick querying. Unlike Redshift, BigQuery is a serverless solution that scales according to usage patterns.
- Snowflake: Unlike Redshift or GCP which rely on their proprietary clouds to operate, Snowflake’s cloud data warehousing capabilities are powered by AWS, Google, Azure, and other public cloud infrastructure. Unlike Redshift, Snowflake allows users to pay separate fees for compute and storage, making the data warehouse a great option for teams looking for a more flexible pay structure.
Why choose a data lake?
Data lakes are the do-it-yourself version of a data warehouse, allowing data engineering teams to pick and choose the various metadata, storage, and compute technologies they want to use depending on the needs of their systems.
Data lakes are ideal for data teams looking to build a more customized platform, often supported by a handful (or more) of data engineers.
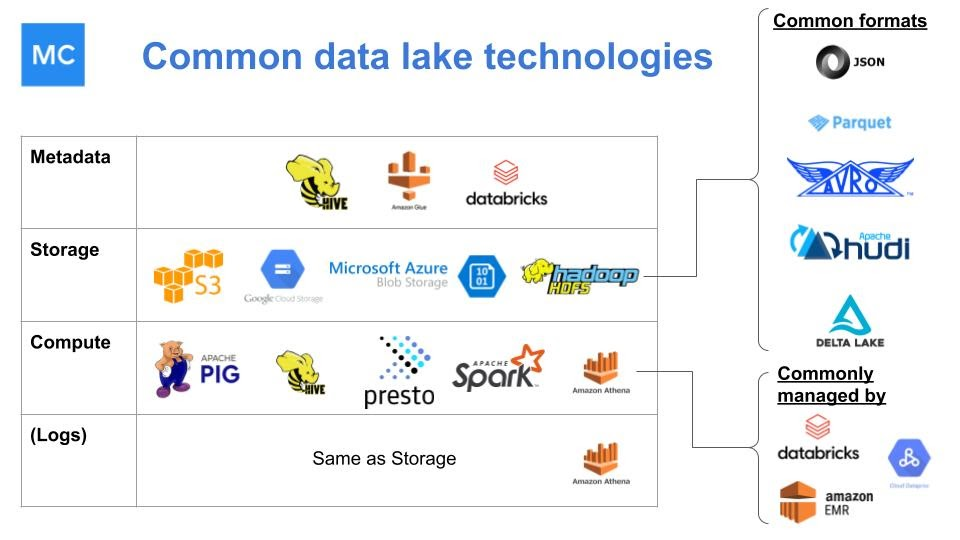
Data lakes are often built with a combination of open source and closed source technologies, making them easy to customize and able to handle increasingly complex workflows. Image courtesy of Lior Gavish/Monte Carlo.
Some common features of data lakes include:
- Decoupled storage and compute: Not only can this functionality allow for substantial cost savings, but it also facilitates parsing and enriching of the data for real-time streaming and querying.
- Strong support for distributed compute: Distributed computing helps support the performance of large-scale data processing because it allows for better segmented query performance, more fault-tolerant design, and superior parallel data processing.
- Customization and interoperability: Owing to their “plug and chug” nature, data lakes support data platform scalability by making it easy for different elements of your stack to play well together as the data needs of your company evolve and mature.
- Largely built on open source technologies: This facilitates reduced vendor lock-in, and affords great customization, which works well for companies with large data engineering teams.
- Ability to handle unstructured or weakly structured data: Data lakes and some data warehouses (like Snowflake and BigQuery) can support raw data, meaning that you have greater flexibility when it comes to working with your data, ideal for data scientists and data engineers. Working with raw data gives you more control over your aggregates and calculations.
- Supports sophisticated non-SQL programming models: Many data lakes support Apache Hadoop, Apache Spark, PySpark, and other frameworks for advanced data science and machine learning.
It’s important to note that many warehouses, such as Snowflake and BigQuery, now support several of these functionalities, too.
Just when you thought the decision was tough enough, another data warehousing option has emerged as an increasingly popular one, particularly among data engineering teams.
Meet the data lakehouse, a solution that marries features of both data warehouses and data lakes, and as a result, combines traditional data analytics technologies with those built for more advanced computations (i.e., machine learning).

The data lakehouse gives data teams even greater customizability, allowing them to store data on the cloud and leverage a warehouse solely for its compute engine. Image courtesy of Lior Gavish/Monte Carlo.
Data lakehouses first came onto the scene when cloud warehouse providers began adding features that offer lake-style benefits, such as Redshift Spectrum or Delta Lake. Similarly, data lakes have been adding technologies that offer warehouse-style features, such as SQL functionality and schema.
Today, the historical differences between warehouses and lakes are narrowing so you can access the best of both words in one package.
The following functionalities are helping data lakehouses further blur the lines between the two technologies:
- High-performance SQL: technologies like Presto and Spark provide SQL interface at close to interactive speeds over data lakes. This opened the possibility of data lakes serving analysis and exploratory needs directly, without requiring summarization and ETL into traditional data warehouses.
- Schema: file formats like Parquet introduced more rigid schema to data lake tables, as well as a columnar format for greater query efficiency.
- Atomicity, Consistency, Isolation, and Durability (ACID): lake technologies like Delta Lake and Apache Hudi introduced greater reliability in write/read transactions, and takes lakes a step closer to the highly desirable ACID properties that are standard in traditional database technologies.
- Managed services: for teams that want to reduce the operational lift associated with building and running a data lake, cloud providers offer a variety of managed lake services. For example, Databricks offers a managed version of Apache Hive, Delta Lake, and Apache Spark while Amazon Athena offers a fully managed lake SQL query engine and Amazon’s Glue offers a fully managed metadata service.
With the rise of real-time data aggregation and streaming to inform lightspeed analytics (think Silicon Valley speeds: Uber, DoorDash, and Airbnb), data lakehouses are likely to rise in popularity and relevance for data teams across industries in the coming years.
So, what should you choose?
There’s not an easy answer. In fact, it’s no surprise that data teams frequently migrate from one data warehouse solution to another as the needs of their data organization shifts and evolves to meet the demands of data consumers (which nowadays, is nearly every functional area in the business, from Marketing and Sales to Operations and HR).
While data warehouses often make sense for data platforms whose primary use case is for data analysis and reporting, data lakes are becoming increasingly user-friendly.
We find that regardless of the route you choose, it’s important to apply the following best practices:
Choose the solution that maps to your company’s data goals.
If your company only uses one or two key data sources on a regular basis for a select few workflows, then it might not make sense to build a data lake from scratch, both in terms of time and resources. But if your company is trying to use data to inform everything under the sun, then a hybrid warehouse-lake solution may just be your ticket to fast, actionable insights for users across roles.
Know who your core users will be.
Will the primary users of your data platform be your company’s business intelligence team, distributed across several different functions? What about a dedicated team of data engineers? Or a few groups of data scientists running A/B tests with various data sets? All of the above? Regardless, choose the data warehouse/lake/lakehouse option that makes the most sense for the skill sets and needs of your users.
Don’t forget data observability.
Data warehouse, data lake, data lakehouse: it doesn’t matter. All three solutions (and any combination of them) will require a holistic approach to data governance and data quality.
After all, your data platform is only as powerful and reliable as the data that informs it; if your data is broken, missing, or otherwise inaccurate (we call this problem data downtime), it doesn’t matter how advanced your pipelines are.
Your thoughtful investment in the latest and greatest data warehouse doesn’t matter if you can’t trust your data. To address this problem, some of the best data teams are leveraging data observability, an end-to-end approach to monitoring and alerting for issues in your data pipelines.
More on that in a future article.
Author: Doron Shachar, CEO Renova Cloud


