

Greenfeed
Data optimization solution on AWS
Greenfeed's mission is to provide consumers with a clean food chain from farm to table with the 3F Plus process - FARM FEED FOOD.

Industry
Agriculture
Technology
OVERVIEW
Established in 2003, Greenfeed’s mission is to provide consumers with a clean food chain from farm to table with the 3F Plus process – FARM FEED FOOD. During the time operating the process, Renova Cloud is honored to cooperate and accompany with Greenfeed to provide AWS solutions.
KEY CHALLENGES
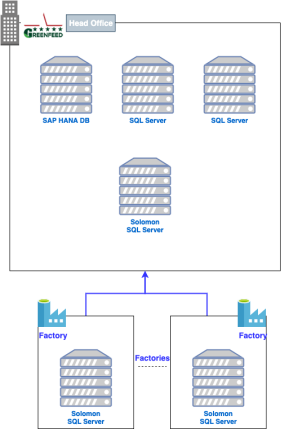
GreenFeed produces and sells agricultural products in a large scale in multiple South East Asian countries. To keep track of the sales and performance of the company, the data stored in various locations and services needs to be combined in reports.
In the past, to make daily sales reports, GreenFeed used the templates on Excel and collected information from various data sources such as: SAP system, Solomon ERP system at factories in Vietnam, Laos, Cambodia, Myanmar and from many excel files.
Because the data is disintegrated and was managed by different departments, it took a lot of time and had to work manually step by step to collect information and complete a synthesis report.
Following the current trend, when data becomes one of the biggest and most valuable assets of enterprises, the methods of storing and analyzing data can influence business decisions. Advanced analytics and business intelligence (BI) reporting tools are the basis which organizations are applying to promote the development in current competitive economy. Therefore, GreenFeed has the following requirements:
- Build a single data lake, which can store all data from all different sources to support for making reports: SAP system, Solomon system, Excel files.
- Build an automated reporting solution that will automatically update the latest data every day and create a daily sales revenue report. Directorate and users will access through the web portal or mobile phone to view the reports.
- Data lake to have unlimited storage space and can store data from other source data in the future such as other databases, external source data (from partners, network social),…
SOLUTION
The key questions are:
- How can we extract data from the SAP system?
- How can we extract data from the Solomon system with all foreign sites?
- How will the data from Excel affect reports?
- How can we automate the process?
- And how can the solution be native to AWS so that it will be easy for customers to use?
First, to be able to extract data from sources to AWS, we will need to establish a secure connection because we cannot push the data out to the internet for such extraction, which is very dangerous. So we will use AWS’s Site to Site VPN to create VPN routes from the AWS network down to GreenFeed’s office, as well as in foreign sites.
Regarding data extraction, we can make use of AWS DMS (Database Migration Service) service, but unfortunately, DMS does not support SAP and GreenFeed’s Solomon SQL Server is an old version which DMS does not support. So we can only build a script to extract the data and Python will be the main language.
For SAP source, we create applications using SAM CLI. By using SAM CLI, we only need to take care of our coding, SAM will help us deploy to Lambda Function AWS. With SAP source, we will divide into 2 sources and extract as follows:
- Data for Dimension Tables
- With the data for Dimension, we will make a call to SAP’s Odata API to fully load the data into S3 as csv file. Then we will COPY data from S3 into Redshift.
- Data for Data Table
- With data for Fact Table, we will also call SAP’s Odata API to load historical data first, then load daily incremental data put it in S3. From S3 we will also COPY the data into Redshift
For the Solomon source, we make a Python Script to extract the data and put it into S3. Because Solomon’s data is quite small, we can use Redshift Spectrum to query data from Redshift to S3 without the need of putting data from S3 into Redshift. For more convenience in querying, we will have a Glue Job to adjust the Struct Type of the entire table and convert it to Parquet format.
For Excel, we upload directly to S3 and load into Redshift using the COPY Command.
Next, we will automatic above steps:
- For SAP, we will put Lambda Functions created from SAM CLI into a Step Function for each data type: Data for Dimension, Data for Fact. With Fact data, Step Function will have an extra step of getting the current date and running a stored procedure to load data into Redshift incrementally. With Dimension Data Step Function, we will load fully into S3 and then Evenbridge will trigger a query to run Storing Procedure to load Dimension data into Redshift.
- For Solomon SQL Server, the script is located in an EC2 server, so we will use the Window Scheduler to schedule the data extraction. AWS Glue can schedule itself to convert back to parquet with the new data.
- For Excel, we also use EventBridge to trigger stored procedures to load data into Redshift.
- After the data from the sources has been loaded into Redshift, we will trigger the Store Procedures to load the data from Redshift’s Staging into the Data warehouse

BENEFITS
- The data lake/data warehouse system on AWS and the reports on the Power BI platform have brought great benefits to GF such as:
- A data lake system can store all structured and unstructured data. AWS tools/services will support GF to ETL different data sources to data lake.
- Easily view automated BI reports. The data ETL processes have been set up to flow automatically to the data lake every day, then Power BI will automatically connect and build the daily sales reports which is required by the GF (the picture below is an example of the sales report on mobile interface)
- The scalability of the data lake system can fully meet GF’s future advanced analysis requirements, as well as apply AI/ML technologies to make important reports and decisions of the enterprise’s business activities.



